SAGE
: Semantic-aware Generation of Multi-view Portrait Drawings
IJCAI 2023
- Biao Ma 1
- Fei Gao 2,3
- Chang Jiang 1
- Nannan Wang 4
- Gang Xu 1
- 1 Hangzhou Dianzi University
- 2 Hangzhou Institute of Technology, Xidian University
- 3 AiSketcher Tech
- 4 ISN State Key Laboratory, Xidian University






Abstract
Neural radiance fields (NeRF) based methods have shown amazing performance in synthesizing 3D-consistent photographic images, but fail to generate multi-view portrait drawings. The key is that the basic assumption of these methods -- a surface point is consistent when rendered from different views -- doesn't hold for drawings. In a portrait drawing, the appearance of a facial point may changes when viewed from different angles. Besides, portrait drawings usually present little 3D information and suffer from insufficient training data. To combat this challenge, in this paper, we propose a Semantic-Aware GEnerator (SAGE) for synthesizing multi-view portrait drawings. Our motivation is that facial semantic labels are view-consistent and correlate with drawing techniques. We therefore propose to collaboratively synthesize multi-view semantic maps and the corresponding portrait drawings. To facilitate training, we design a semantic-aware domain translator, which generates portrait drawings based on features of photographic faces. In addition, use data augmentation via synthesis to mitigate collapsed results. We apply SAGE to synthesize multi-view portrait drawings in diverse artistic styles. Experimental results show that SAGE achieves significantly superior or highly competitive performance, compared to existing 3D-aware image synthesis methods.
Pipeline
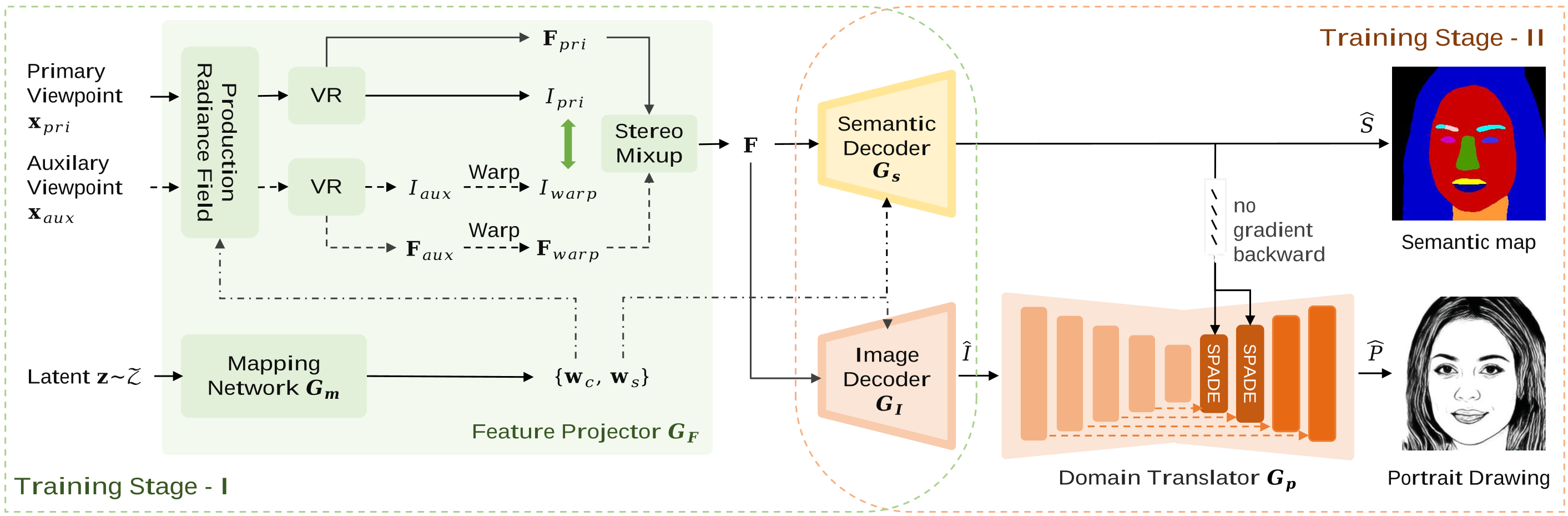
Pipeline of our semantic-aware portrait drawing generator, SAGE. The feature projector GF generates feature maps F> and normalization parameters w, which control content and viewpoints of generated faces. In Stage-I, we train the feature projector GF, semantic decoder Gs, and image decoder GI to enable the generator producing multi-view facial photos and semantic masks. In Stage-II, we add the portrait drawing decoder Gp, and refine all decoders for synthesizing high quality portrait drawings based on features of photographic faces.
Generation Results





